Introduction
This guide provides a comprehensive overview of various health checks that can be performed to assess the functionality and stability of your platform. These checks should be performed after a platform upgrade to ensure that everything works correctly and that no new issues have been introduced.
Health Checks
Some of these health checks rely on the use of the sre-admin tool, while others depend on OS commands or subsystem monitoring commands.
TIP
On some systems, the sre-admin tool may complain about the locales not being correctly set at the OS level. If this occurs, you can set it to a default locale with the following command: export LC_ALL=en_US.utf8.
Global Status
Target servers: master EM
The sre-admin tool can be used to check the global status of the system with /opt/sre/bin/sre-admin status. This command provides status about various information collected from all the EMs and CPs, including:
- DB status
- DB replication status
- active connections on local DB
- SRE processes status
- CPU and RAM usage
Example:
[root@SRE-33-EM1 ~]# /opt/sre/bin/sre-admin status
Server DB status
Hostname Status
---------- --------
SRE-33-EM1 master
Server DB replication status
Client Address State Started WAL sent WAL written WAL flushed WAL replayed
-------- ------------ --------- --------- ---------- ------------- ------------- --------------
cp2 10.0.161.183 streaming 10:20:38 F/605F7F68 F/605F7F68 F/605F7F68 F/605F7F68
em2 10.0.161.181 streaming 09:09:22 F/605F7F68 F/605F7F68 F/605F7F68 F/605F7F68
cp1 10.0.161.182 streaming 09:30:21 F/605F7F68 F/605F7F68 F/605F7F68 F/605F7F68
Server DB activity
Client Address Username PID DB Last state change State Query
-------- ------------ ---------- ----- ------------------------------ --------------------- ------- -------------------------------------------------------------------------------------------------------------------------------------------
5241
postgres 5243
127.0.0.1 sre 18502 sre 12:01:45 (1292118.09) idle ROLLBACK
127.0.0.1 sre 15258 sre 12:04:52 (82330.90) idle ROLLBACK
127.0.0.1 sre 31533 sre 10:57:02 (0.31) idle ROLLBACK
127.0.0.1 sre 31211 sre 10:57:02 (0.56) idle ROLLBACK
127.0.0.1 sre 18510 sre 12:01:50 (1292112.35) idle ROLLBACK
127.0.0.1 sre 31431 sre 10:56:06 (56.69) idle ROLLBACK
127.0.0.1 postgres 18522 postgres 10:57:00 (2.95) idle SELECT * FROM pg_stat_bgwriter
...
127.0.0.1 sre 31216 sre 10:57:02 (0.56) idle ROLLBACK
127.0.0.1 sre 2322 sre 10:57:03 (0.01) active SELECT datname,pid,usename,application_name,client_addr,backend_start,xact_start,query_start,state_change,state,query FROM pg_stat_activity
5239
5238
5240
Platform process status
Process/Server SRE-33-CP1 SRE-33-CP2 SRE-33-EM1 SRE-33-EM2
--------------------- --------------------------------------------- -------------------------------------------- --------------------------------------------- ---------------------------------------------
sre-REST STOPPED STOPPED RUNNING (pid 18463, uptime 14 days, 22:55:35) RUNNING (pid 28206, uptime 14 days, 22:55:05)
sre-agents-monitor RUNNING (pid 17243, uptime 8 days, 1:09:08) RUNNING (pid 3113, uptime 8 days, 1:04:36) STOPPED STOPPED
sre-broker RUNNING (pid 16207, uptime 14 days, 22:55:48) RUNNING (pid 7436, uptime 14 days, 22:55:49) STOPPED STOPPED
sre-call-processor:0 RUNNING (pid 16208, uptime 14 days, 22:55:48) RUNNING (pid 7437, uptime 14 days, 22:55:49) STOPPED STOPPED
sre-cdr-collector STOPPED STOPPED RUNNING (pid 18464, uptime 14 days, 22:55:35) RUNNING (pid 28207, uptime 14 days, 22:55:05)
sre-cdr-postprocessor STOPPED STOPPED STOPPED STOPPED
sre-cdr-sender RUNNING (pid 16210, uptime 14 days, 22:55:48) RUNNING (pid 7438, uptime 14 days, 22:55:49) STOPPED STOPPED
sre-dns-updater STOPPED STOPPED STOPPED STOPPED
sre-enum-processor RUNNING (pid 16211, uptime 14 days, 22:55:48) RUNNING (pid 7439, uptime 14 days, 22:55:49) STOPPED STOPPED
sre-gui STOPPED STOPPED RUNNING (pid 18465, uptime 14 days, 22:55:35) RUNNING (pid 28208, uptime 14 days, 22:55:05)
sre-health-monitor RUNNING (pid 16212, uptime 14 days, 22:55:48) RUNNING (pid 7440, uptime 14 days, 22:55:49) RUNNING (pid 18466, uptime 14 days, 22:55:35) RUNNING (pid 28209, uptime 14 days, 22:55:05)
sre-http-processor RUNNING (pid 16213, uptime 14 days, 22:55:48) RUNNING (pid 7441, uptime 14 days, 22:55:49) RUNNING (pid 18467, uptime 14 days, 22:55:35) RUNNING (pid 28210, uptime 14 days, 22:55:05)
sre-manager STOPPED STOPPED RUNNING (pid 26712, uptime 10:57:02) RUNNING (pid 13034, uptime 12 days, 10:56:57)
Platform system status
Metric/Server SRE-33-CP1 SRE-33-CP2 SRE-33-EM1 SRE-33-EM2
--------------- ------------ ------------ ------------ ------------
CPU 8.8 % 16.2 % 44.7 % 13.2 %
Memory 43.5 % 49.3 % 48.3 % 64.4 %
Swap 4.0 % 8.0 % 4.9 % 4.5 %SRE Process
Target servers: EMs and CPs
You may check that the SRE processes are running by executing the systemctl status sre command.
Example:
[root@sre-40-em1 ~]# systemctl status sre
* sre.service - SRE is a centralized, multi interface Session Routing Engine.
Loaded: loaded (/usr/lib/systemd/system/sre.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2024-06-05 12:01:26 CEST; 2 weeks 1 days ago
Docs: https://www.netaxis.be/products/session-routing-engine/
Main PID: 18447 (supervisord)
CGroup: /system.slice/sre.service
|-18447 /opt/sre/bin/python /opt/sre/bin/supervisord -n
|-18463 /opt/sre/bin/python /opt/sre/bin/sre-REST
|-18464 /opt/sre/bin/python /opt/sre/bin/sre-cdr-collector
|-18465 /opt/sre/bin/python /opt/sre/bin/sre-gui
|-18466 /opt/sre/bin/python /opt/sre/bin/sre-health-monitor
|-18467 /opt/sre/bin/python /opt/sre/bin/sre-http-processorDatabase Process
Target servers: EMs and CPs
You may check that the Database processes are running by executing the systemctl status postgresql-14 command.
[root@sre-40-em1 ~]# systemctl status postgresql-14
* postgresql-14.service - PostgreSQL 14 database server
Loaded: loaded (/usr/lib/systemd/system/postgresql-14.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2024-06-05 08:47:27 CEST; 2 weeks 1 days ago
Docs: https://www.postgresql.org/docs/14/static/
Main PID: 5234 (postmaster)
CGroup: /system.slice/postgresql-14.service
|- 5234 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
|- 5236 postgres: logger
|- 5238 postgres: checkpointer
|- 5239 postgres: background writer
|- 5240 postgres: walwriter
|- 5241 postgres: autovacuum launcher
|- 5242 postgres: stats collector
|- 5243 postgres: logical replication launcher
|- 7353 postgres: walsender repmgr 10.0.161.181(40814) streaming F/60DFDC00
|- 8854 postgres: walsender repmgr 10.0.161.182(47168) streaming F/60DFDC00
|-11921 postgres: walsender repmgr 10.0.161.183(44226) streaming F/60DFDC00
|-17337 postgres: sre sre 127.0.0.1(43842) idle
|-17339 postgres: sre sre 127.0.0.1(43884) idle
|-17606 postgres: sre sre 127.0.0.1(49254) idle
|-17687 postgres: sre sre 127.0.0.1(50974) idle
...
|-19049 postgres: sre datamodel_a 127.0.0.1(46566) idle
`-19050 postgres: sre datamodel_b 127.0.0.1(46568) idleINFO
The number of running processes for the database can fluctuate. For instance, processes managing connections to specific databases may only appear after a call processor has received some requests.
TIP
The presence of the walsender process indicates that this instance is sending replication information to a standby DB, along with its IP address. On a standby DB instance, the presence of the process walreceiver indicates the receiving process side.
Call Admission Control Database Process
Target servers: EMs (if activated) and CPs
INFO
This check is relevant only if the CAC database (MongoDB-based) was installed on the deployment.
You may check that the CAC DB is running by executing the systemctl status mongod command:
[root@sre-40-em1 ~]# systemctl status mongod
* mongod.service - MongoDB Database Server
Loaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-06-18 09:41:58 UTC; 2 days ago
Docs: https://docs.mongodb.org/manual
Main PID: 23435 (mongod)
CGroup: /system.slice/mongod.service
`-23435 /usr/bin/mongod -f /etc/mongod.confStatistics Database Process
Target servers: EMs
You may check that the statistics DB is running by executing the systemctl status influxdb command.
[root@sre-40-em1 ~]# systemctl status influxdb
* influxdb.service - InfluxDB is an open-source, distributed, time series database
Loaded: loaded (/usr/lib/systemd/system/influxdb.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2024-05-27 14:14:48 CEST; 3 weeks 3 days ago
Docs: https://docs.influxdata.com/influxdb/
Main PID: 943 (influxd)
CGroup: /system.slice/influxdb.service
`-943 /usr/bin/influxdMain Database Replication
Target servers: master EM
On master EM, you can check the main database replication status with the command sudo -u postgres psql -c "select * from pg_stat_replication"
Example:
[root@SRE-33-EM1 ~]# sudo -u postgres psql -c "select * from pg_stat_replication"
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+---------+------------------+--------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------+------------------------
-------
11921 | 16389 | repmgr | cp2 | 10.0.161.183 | | 44226 | 2024-06-05 10:20:38.500267+02 | | streaming | F/607CF740 | F/607CF740 | F/607CF740 | F/607CF740 | 00:00:00.000919 | 00:00:00.002584 | 00:00:00.003398 | 0 | async | 2024-06-20 12:18:27.489
589+02
7353 | 16389 | repmgr | em2 | 10.0.161.181 | | 40814 | 2024-06-05 09:09:22.959677+02 | | streaming | F/607CF740 | F/607CF740 | F/607CF740 | F/607CF740 | 00:00:00.000891 | 00:00:00.002693 | 00:00:00.003573 | 0 | async | 2024-06-20 12:18:27.489
033+02
8854 | 16389 | repmgr | cp1 | 10.0.161.182 | | 47168 | 2024-06-05 09:30:21.685879+02 | | streaming | F/607CF740 | F/607CF740 | F/607CF740 | F/607CF740 | 00:00:00.000559 | 00:00:00.001348 | 00:00:00.002113 | 0 | async | 2024-06-20 12:18:27.488
924+02
(3 rows)Call Admission Control Database Replication
Target servers: EMs (if activated) and CPs
On any node where MongoDB is activated, run the command mongo --eval 'rs.status()' to return the list of different members belonging to the replica set as well as their current state. There should be only one PRIMARY node and several SECONDARY nodes. Optionally, there may be one or more ARBITER nodes. No nodes should be in other states, such as RECOVERING or others.
The fields lastAppliedWallTime and lastHeartbeat should be recent for all members.
[root@sre-cp1 ~]# mongo --eval 'rs.status()'
MongoDB shell version v5.0.26
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("59806e01-1811-4d4d-988e-3b696e683316") }
MongoDB server version: 5.0.26
{
"set" : "sre_location",
"date" : ISODate("2024-06-20T10:20:42.319Z"),
"myState" : 2,
"term" : NumberLong(1),
"syncSourceHost" : "10.0.161.64:27017",
"syncSourceId" : 3,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 3,
"writeMajorityCount" : 3,
"votingMembersCount" : 4,
"writableVotingMembersCount" : 4,
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"lastCommittedWallTime" : ISODate("2024-06-20T10:20:40.383Z"),
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"lastAppliedWallTime" : ISODate("2024-06-20T10:20:40.383Z"),
"lastDurableWallTime" : ISODate("2024-06-20T10:20:40.383Z")
},
"lastStableRecoveryTimestamp" : Timestamp(1718878830, 1),
"members" : [
{
"_id" : 0,
"name" : "10.0.161.60:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 175121,
"optime" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2024-06-20T10:20:40Z"),
"optimeDurableDate" : ISODate("2024-06-20T10:20:40Z"),
"lastAppliedWallTime" : ISODate("2024-06-20T10:20:40.383Z"),
"lastDurableWallTime" : ISODate("2024-06-20T10:20:40.383Z"),
"lastHeartbeat" : ISODate("2024-06-20T10:20:41.142Z"),
"lastHeartbeatRecv" : ISODate("2024-06-20T10:20:40.352Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1712329875, 1),
"electionDate" : ISODate("2024-04-05T15:11:15Z"),
"configVersion" : 1,
"configTerm" : 1
},
{
"_id" : 1,
"name" : "10.0.161.62:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 175124,
"optime" : {
"ts" : Timestamp(1718878840, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2024-06-20T10:20:40Z"),
"lastAppliedWallTime" : ISODate("2024-06-20T10:20:40.383Z"),
"lastDurableWallTime" : ISODate("2024-06-20T10:20:40.383Z"),
"syncSourceHost" : "10.0.161.64:27017",
"syncSourceId" : 3,
"infoMessage" : "",
"configVersion" : 1,
"configTerm" : 1,
"self" : true,
"lastHeartbeatMessage" : ""
},
...
],
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1718878840, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1718878840, 1)
}Statistics Production
Target servers: master EM
The sre-manager process writes the statistics collected from different nodes to CSV files every minute. Check the content of the CSV file /var/log/sre/counters.csv to ensure that calls are being processed and statistics are being generated. The format of this file is:
- hostname
- metric name
- timestamp (human-readable format)
- timestamp (EPOCH timestamp)
- 15 fields with the metric value, one per minute, from the most recent to the oldest
For an SRE with active traffic, the metric request.INVITE should indicate the presence of calls being processed. The presence of response.relay metrics indicate that calls have bee relayed by the Service Logic.
Example:
[root@sre-em1-ams-dune ~]# cat /var/log/sre/counters.csv
sre-cp1-ams-dune,request.INVITE,2024-06-20T10:39:00,1718879940,16,20,23,19,18,20,24,23,21,21,26,24,21,21,19
sre-cp2-ams-dune,request.INVITE,2024-06-20T10:39:00,1718879940,0,0,1,0,0,0,0,0,0,0,1,0,0,0,0
sre-cp1-ams-dune,request.OPTIONS,2024-06-20T10:39:00,1718879940,7,6,6,6,6,6,7,7,7,5,6,7,6,7,7
sre-cp1-ams-dune,request.REGISTER,2024-06-20T10:39:00,1718879940,2,1,1,3,0,5,0,1,0,3,2,0,1,3,2
sre-cp1-ams-dune,response.200 (OPTIONS),2024-06-20T10:39:00,1718879940,7,6,6,6,6,6,7,7,7,5,6,7,6,7,7
sre-cp1-ams-dune,response.authenticate,2024-06-20T10:39:00,1718879940,5,2,1,2,1,5,2,1,1,2,2,0,2,2,1
sre-cp1-ams-dune,response.locationServiceRelay,2024-06-20T10:39:00,1718879940,1,2,0,0,1,0,2,1,0,0,0,1,0,2,2
sre-cp1-ams-dune,response.locationServiceSave,2024-06-20T10:39:00,1718879940,2,1,1,1,0,3,0,1,0,2,1,0,1,1,1
sre-cp1-ams-dune,response.proxySIPError,2024-06-20T10:39:00,1718879940,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0
sre-cp1-ams-dune,response.relay,2024-06-20T10:39:00,1718879940,15,19,23,19,17,20,22,23,21,21,26,22,20,19,16
sre-cp2-ams-dune,response.relay,2024-06-20T10:39:00,1718879940,0,0,1,0,0,0,0,0,0,0,1,0,0,0,0SIP Stack
Target servers: CPs
The command kamctl stats provide statistics about the SIP stack processing. This command should be run twice to verify the increase of the counters. Among these, core:rcv_requests, core:rcv_requests_invite, core:rcv_replies and core:fwd_requests should increase under traffic conditions.
Example:
[root@sre-cp1-ams-dune /]# kamctl stats
{
"jsonrpc": "2.0",
"result": [
"app_python3:active_dialogs = 167",
"app_python3:early_dialogs = 0",
"app_python3:expired_dialogs = 0",
"app_python3:failed_dialogs = 709",
"app_python3:processed_dialogs = 21047",
"core:bad_URIs_rcvd = 0",
"core:bad_msg_hdr = 0",
"core:drop_replies = 0",
"core:drop_requests = 465",
"core:err_replies = 0",
"core:err_requests = 0",
"core:fwd_replies = 2",
"core:fwd_requests = 24173",
"core:rcv_replies = 98268",
"core:rcv_replies_18x = 18432",
...
"core:rcv_replies_6xx_reg = 0",
"core:rcv_replies_6xx_update = 0",
"core:rcv_requests = 109766",
"core:rcv_requests_ack = 25120",
"core:rcv_requests_bye = 20026",
"core:rcv_requests_cancel = 382",
"core:rcv_requests_info = 0",
"core:rcv_requests_invite = 25584",
"core:rcv_requests_message = 0",
"core:rcv_requests_notify = 0",
"core:rcv_requests_options = 21065",
"core:rcv_requests_prack = 13620",
"core:rcv_requests_publish = 0",
"core:rcv_requests_refer = 0",
"core:rcv_requests_register = 3911",
"core:rcv_requests_subscribe = 0",
"core:rcv_requests_update = 58",
"core:unsupported_methods = 0",
"dns:failed_dns_request = 0",
"dns:slow_dns_request = 0",
"registrar:accepted_regs = 2088",
"registrar:default_expire = 3600",
"registrar:default_expires_range = 0",
"registrar:expires_range = 0",
"registrar:max_contacts = 1",
"registrar:max_expires = 3600",
"registrar:rejected_regs = 0",
"shmem:fragments = 101",
"shmem:free_size = 63602864",
"shmem:max_used_size = 4053816",
"shmem:real_used_size = 3506000",
"shmem:total_size = 67108864",
"shmem:used_size = 3077096",
...
],
"id": 22673
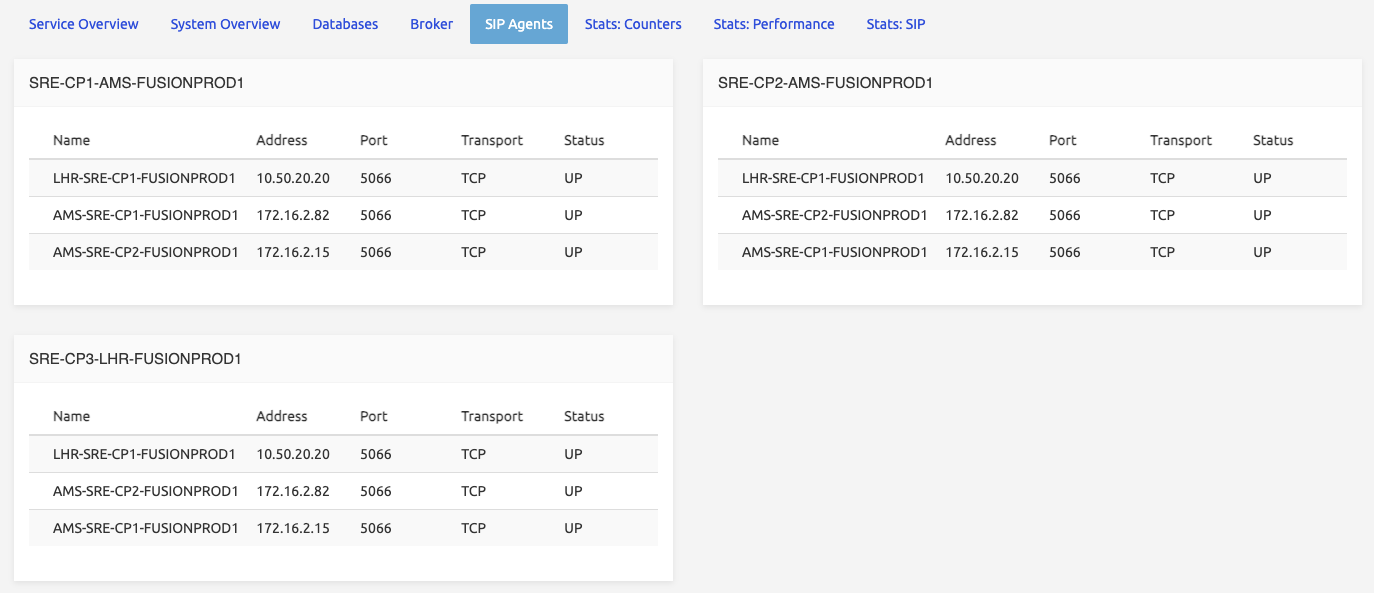
}SIP Agents Monitoring
Target servers: master EM
The status of the SIP agents monitored by SRE can be viewed from the GUI dashboard under the SRE tab. Unless there are known issues with the probed agents, the status of all agents should be UP.
Accounting Generation
Target servers: master EM
Run the command /opt/sre/bin/sre-admin monitor accounting summary to get the count of currently active calls from an accounting point of view.
Example:
[root@SRE-33-EM1 ~]# /opt/sre/bin/sre-admin monitor accounting summary
Hostname Open calls
---------- ------------
total 7List files in the directory /data/sre/accounting/ to ensure that accounting files are properly generated. There should be exactly one CDR file suffixed with .inprogress and a recent timestamp in the filename and possibly several CDR files that are not updated anymore.
Example:
[sre@SRE-33-EM1 ~]$ ls -lrt /data/sre/accounting/
total 124216
drwxrwxr-x. 3 sre sre 19 Mar 19 14:09 http
drwxrwxr-x. 2 sre sre 6 Mar 19 14:09 events
drwxrwxr-x. 3 sre sre 19 Mar 19 14:09 enum
-rw-r--r-- 1 sre sre 46866966 Jun 20 13:04 cdr-2024-06-20T13:00:00
-rw-r--r-- 1 sre sre 46682213 Jun 20 13:09 cdr-2024-06-20T13:05:00
drwxrwxr-x. 2 sre sre 71 Jun 20 13:13 state
-rw-r--r-- 1 sre sre 28939111 Jun 20 13:13 cdr-2024-06-20T13:10:00.inprogressAccounting Synchronization
Target servers: EMs
The accounting synchronization mechanism between the two EMs can be verified by listing the files in /data/sre/accounting/state. The file suffixed with .checkpoint represents the last checkpoint of the accounting status at that moment and should be identical on both servers. The file suffixed with .oplog contains the delta of accounting information relative to the last checkpoint file. This file is continuously synchronized between both EMs and should be approximately the same size.
Example:
[sre@SRE-33-EM1 ~ ~]$ ls -lrt /data/sre/accounting/state
total 45500
-rw-r--r-- 1 sre sre 29615256 Jun 20 13:15 0000000000003ef3.checkpoint
-rw-r--r-- 1 sre sre 13976487 Jun 20 13:15 0000000000003ef3.oplog
[sre@SRE-33-EM2 ~ ~]$ ls -lrt /data/sre/accounting/state
total 59388
-rw-r--r-- 1 sre sre 29615256 Jun 20 13:15 0000000000003ef3.checkpoint
-rw-r--r-- 1 sre sre 25596460 Jun 20 13:16 0000000000003ef3.oplog